Scrapy基本使用
URL
date
Apr 22, 2022
slug
scrapy
status
Published
tags
Scrapy
summary
Scrapy说明
type
Post
框架的选择Scrapy PySpiderCrawleyPortiaScrapy基本教程参数传递scrapy中的yield scrapy.Request 在传递item 的注意点日志配置使用settings配置301的情况403的情况ImagePipelineCrawlerProcessyield的说明Scrapyd部署Chrome的Network抓包小技巧配合postman测试接口Selemium使用
框架的选择
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
Crawley
Crawley可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Scrapy基本教程
scrapy框架下载文件和图片 https://blog.csdn.net/Zhihua_W/article/details/105200916
xpath如何抓取
创建项目
scrapy startproject coolscrapy运行爬虫
scrapy crawl huxiu参数传递
1、爬取列表信息的方法funcA
2、爬取新闻详情信息的funcB
3、爬取解说的funcC
建议用深拷贝
scrapy中的yield scrapy.Request 在传递item 的注意点
深拷贝
在用scrapy框架的时候在很多情况下会出现要爬取一个列表页面和一个详情页面的情况,这个时候通常会使用yield 来发起一个请求,并通过 callback 参数为这个请求添加回调函数,在请求完成之后会将响应作为参数传递给回调函数,但在我们传递item的时候会出现一些问题:
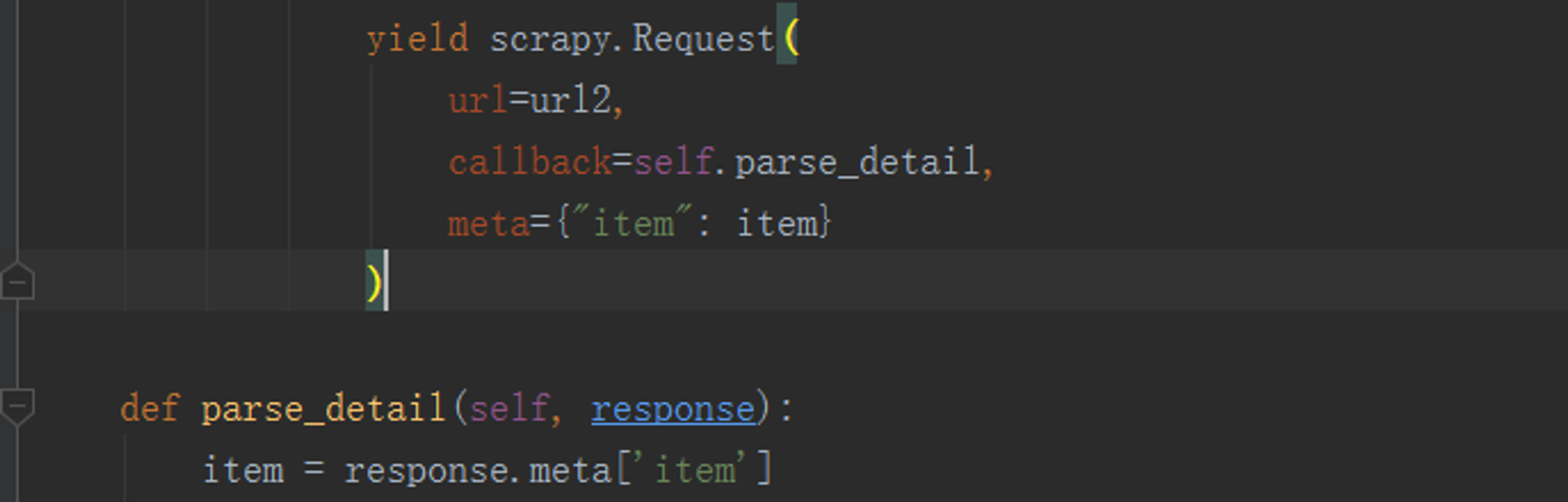
在需要多次调用下面这个parse_detail() 方法的时候,会出现获取到最后一个item的情况,而且是循环调用最后一个,就像是上面yield 这一部分是个for循环,但是下面的parse方法不再循环内,所以就只能一直调用到最后一个item.
解决方法:
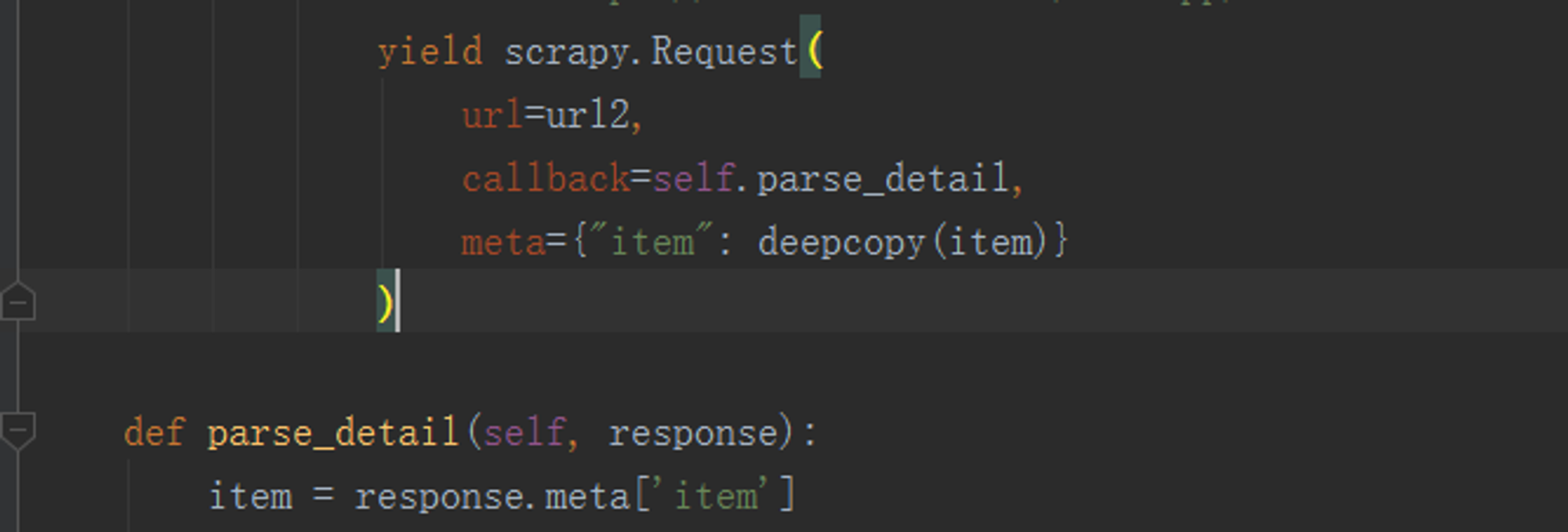
使用deepcopy深层次拷贝item,拷贝每一次引擎收到的item,并将其调给parse_detail()方法
日志配置
提供5层logging级别:
通过在setting.py中进行以下设置可以被用来配置logging
默认值:
配置示例
使用
或者
使用settings配置
可以在自定义
.py 文件,也是比较推荐的mysettings.py在
mytest.py中使用301的情况
在settings中设置
403的情况
在爬 https://hotel.meituan.com/hangzhou/ 美团的一个酒店信息时候,浏览器链接访问正常,但是爬虫报错如下:
解决思路
在默认情况下,scrapy 是不会模拟浏览器去获取信息的,而 HTTP 403 表示服务器获得了请求,但是拒绝提供服务。那么就需要我们配置 用户代理(User-Agent)到scrapy中,对发起的请求进行模拟:
Crawl responsibly by identifying yourself (and your website) on the user-agent
被修改的文件为 setting.py 文件,在 scrapy 框架中路径如下:
添加了 user-agent 后,就可以正常访问网站了。
ImagePipeline
首先要继承
ImagePipelineCrawlerProcess
为了让同一个 Scrapy 项目下面的多个爬虫实现真正的同时运行,我们可以使用 Scrapy 的
CrawlerProcess。它的用法如下:可以在同一个进程里面跑多个爬虫。
yield的说明
Scrapyd部署
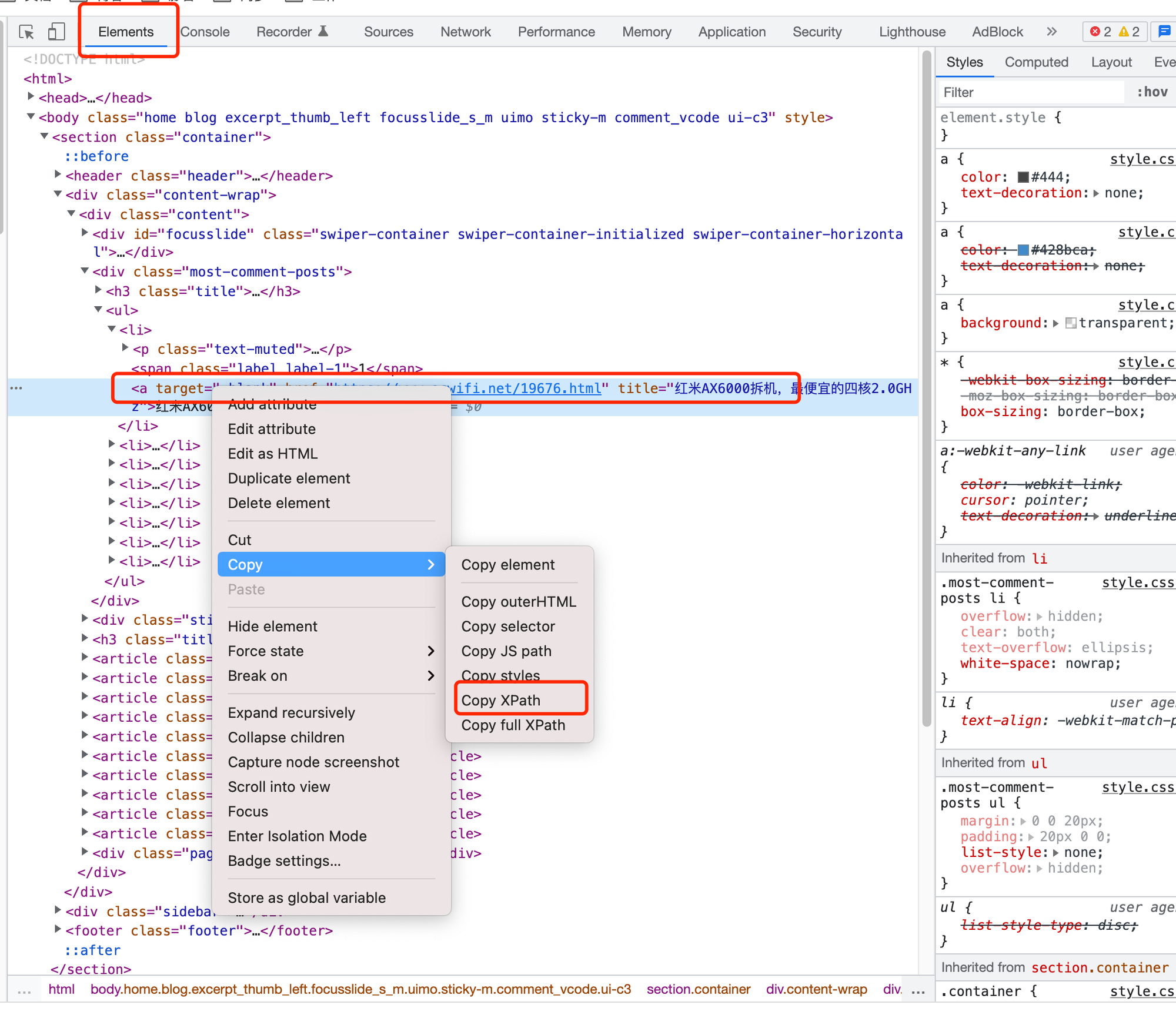
Chrome的Network抓包小技巧
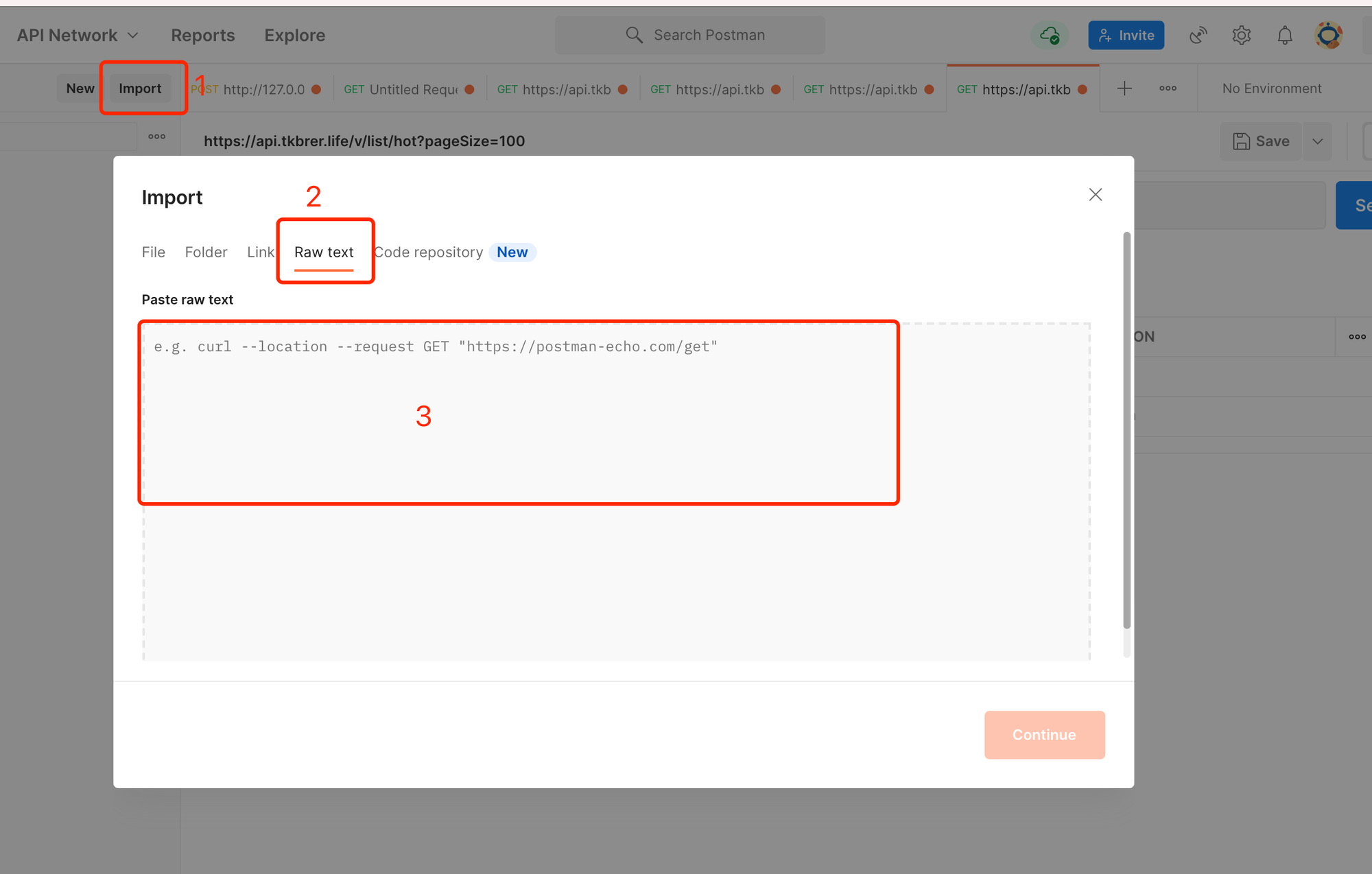
配合postman测试接口
首先找到chrome的network,找到请求详情,copy curl的方式
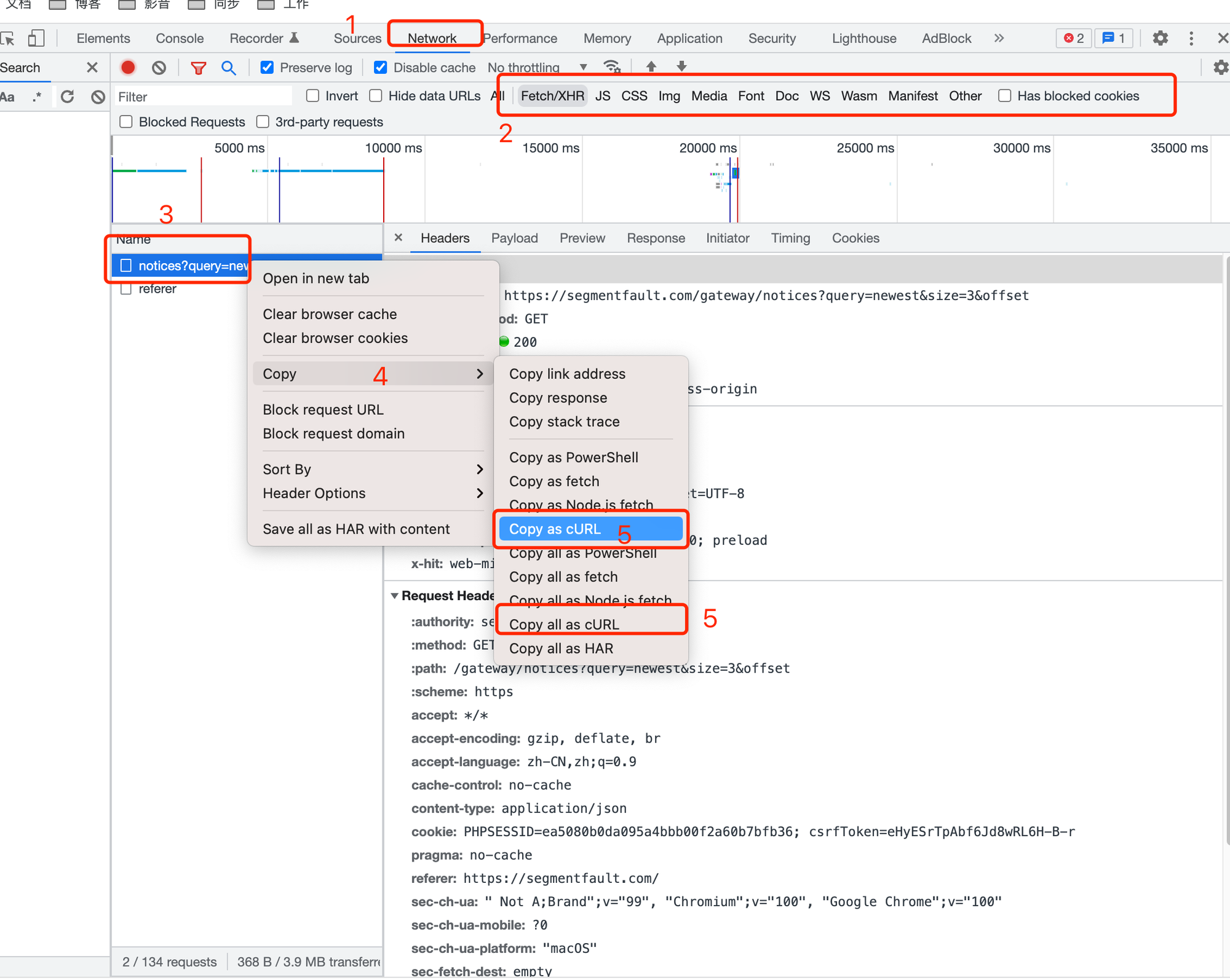
打开postman, 把刚才复制的请求贴进去,然后选择
continue