Postgres安装和基本权限配置
date
Apr 19, 2022
slug
postgres-install
status
Published
tags
Postgres
summary
postgres初入门
type
Post
介绍与安装数据类型兼容性1. 安装Postgres2. 修改postgres账号密码2.1、进入PostgreSQL命令行2.2、启动SQL Shell2.3、修改密码3. 配置远程访问3.1、开放端口3.2、修改IP绑定3.3、允许所有IP访问3.4、重启PostgreSQL服务4. PostgreSQL shell常用语法示例4.1、数据库相关语法示例4.2、用户与访问授权语法示例5. 备注5.1、相关阅读6. 配置自增7. 参数优化空表创建自增健mysql迁移的表结构,更改自增id迁移数据同步表结构同步数据常见差异类型差异简介查看连接的数据里所有用户表的大小查看每个表、索引、toast表的大小查询某表某列所有项的大小查询按外键聚合的字段的总大小json、jsonb类型字段的大小查询每个表的字段信息索引规范数据库规范化设计的一些基本要求:设计规范查询包含联合索引的表信息出现重复字段复制方案Postgres 中使用 Zhparser 插件进行中文全文检索更改owner参考资料
介绍与安装
数据类型
名字 | 别名 | 描述 |
bigint | int8 | 有符号的8字节整数 |
bigserial | serial8 | 自动增长的8字节整数 |
bit [ (n) ] | 定长位串 | |
bit varying [ (n) ] | varbit [ (n) ] | 变长位串 |
boolean | bool | 逻辑布尔值(真/假) |
box | 平面上的普通方框 | |
bytea | 二进制数据(“字节数组”) | |
character [ (n) ] | char [ (n) ] | 定长字符串 |
character varying [ (n) ] | varchar [ (n) ] | 变长字符串 |
cidr | IPv4或IPv6网络地址 | |
circle | 平面上的圆 | |
date | 日历日期(年、月、日) | |
double precision | float8 | 双精度浮点数(8字节) |
inet | IPv4或IPv6主机地址 | |
integer | int, int4 | 有符号4字节整数 |
interval [ fields ] [ (p) ] | 时间段 | |
json | 文本 JSON 数据 | |
jsonb | 二进制 JSON 数据,已分解 | |
line | 平面上的无限长的线 | |
lseg | 平面上的线段 | |
macaddr | MAC(Media Access Control)地址 | |
macaddr8 | MAC(Media Access Control)地址(EUI-64格式) | |
money | 货币数量 | |
numeric [ (p, s) ] | decimal [ (p, s) ] | 可选择精度的精确数字 |
path | 平面上的几何路径 | |
pg_lsn | PostgreSQL日志序列号 | |
pg_snapshot | 用户级事务ID快照 | |
point | 平面上的几何点 | |
polygon | 平面上的封闭几何路径 | |
real | float4 | 单精度浮点数(4字节) |
smallint | int2 | 有符号2字节整数 |
smallserial | serial2 | 自动增长的2字节整数 |
serial | serial4 | 自动增长的4字节整数 |
text | 变长字符串 | |
time [ (p) ] [ without time zone ] | 一天中的时间(无时区) | |
time [ (p) ] with time zone | timetz | 一天中的时间,包括时区 |
timestamp [ (p) ] [ without time zone ] | 日期和时间(无时区) | |
timestamp [ (p) ] with time zone | timestamptz | 日期和时间,包括时区 |
tsquery | 文本搜索查询 | |
tsvector | 文本搜索文档 | |
txid_snapshot | 用户级别事务ID快照(废弃; 参见 pg_snapshot) | |
uuid | 通用唯一标识码 | |
xml | XML数据 |
兼容性
下列类型(或者及其拼写)是SQL指定的:
bigint、bit、bit varying、boolean、char、character varying、character、varchar、date、double precision、integer、interval、numeric、decimal、real、smallint、time(有时区或无时区)、timestamp(有时区或无时区)、xml。1. 安装Postgres
进入官网的下载页面 https://www.postgresql.org/download/
选择操作系统
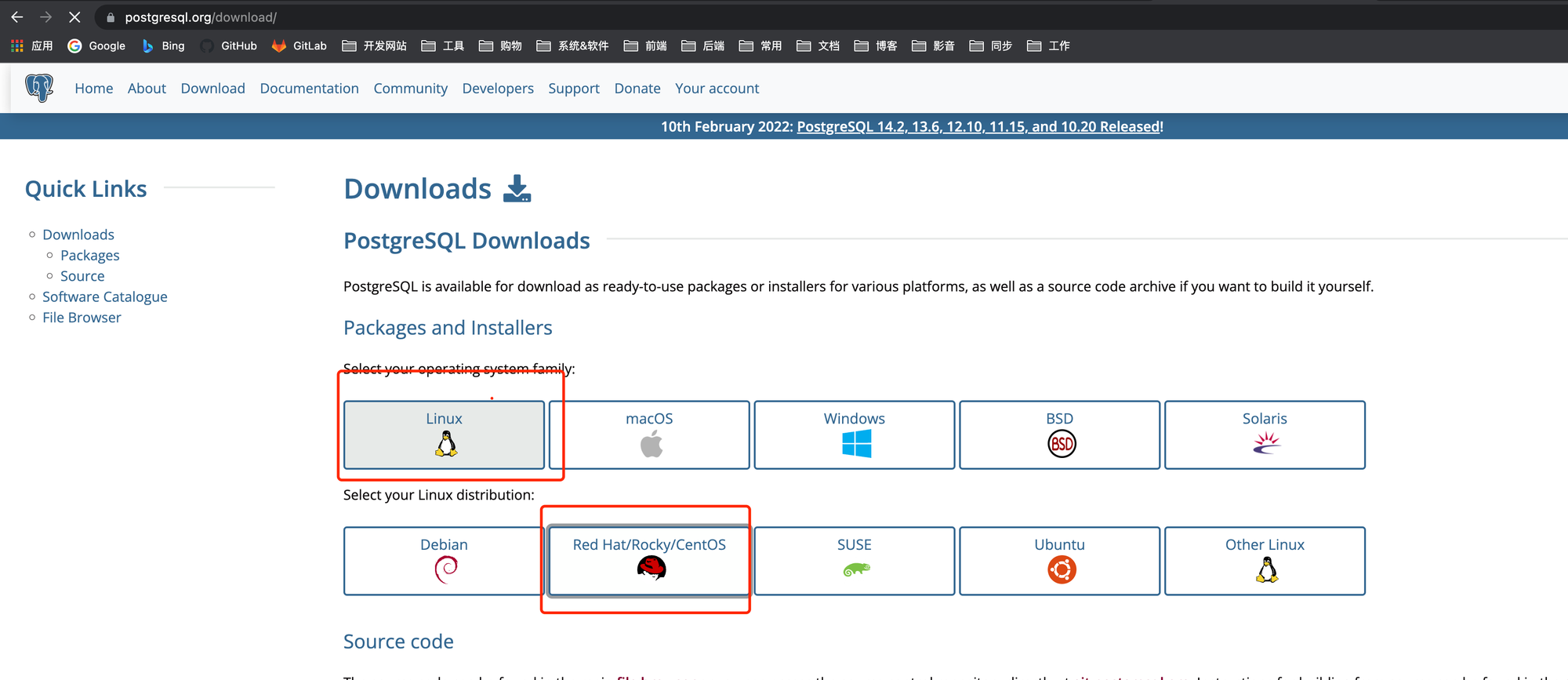
依次选择执行
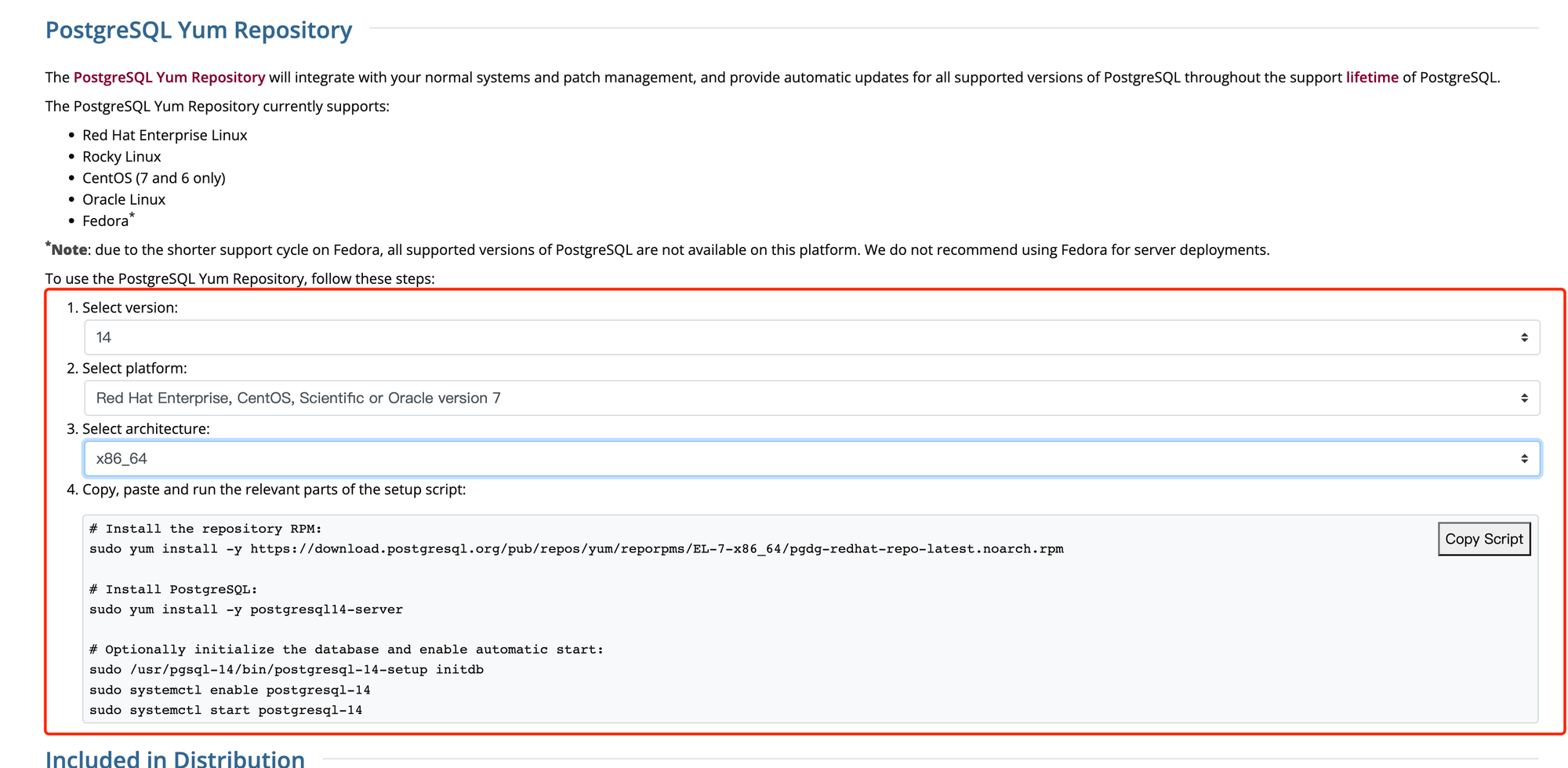
2. 修改postgres账号密码
PostgreSQL安装成功之后,会默认创建一个名为postgres的Linux用户,初始化数据库后,会有名为postgres的数据库,来存储数据库的基础信息,例如用户信息等等,相当于MySQL中默认的名为mysql数据库。
postgres数据库中会初始化一名超级用户
postgres为了方便我们使用postgres账号进行管理,我们可以修改该账号的密码
2.1、进入PostgreSQL命令行
通过su命令切换linux用户为postgres会自动进入命令行
2.2、启动SQL Shell
2.3、修改密码
3. 配置远程访问
3.1、开放端口
3.2、修改IP绑定
3.3、允许所有IP访问
3.4、重启PostgreSQL服务
配置完成后即可使用客户端进行连接
4. PostgreSQL shell常用语法示例
启动SQL shell:
4.1、数据库相关语法示例
4.2、用户与访问授权语法示例
权限代码:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE、USAGE
5. 备注
5.1、相关阅读
6. 配置自增
Mysql中的主键有自增的方法,但是Postgres中并没有自增主键,需要借助类型
- 空表的情况下,创建自增id
- 表结构是从msql迁移过来的,表结构是int类型,并且是主键,如何更改成自增
7. 参数优化
https://pgtune.leopard.in.ua/#/ 在线网站,输入配置和连接数,即可生成配置
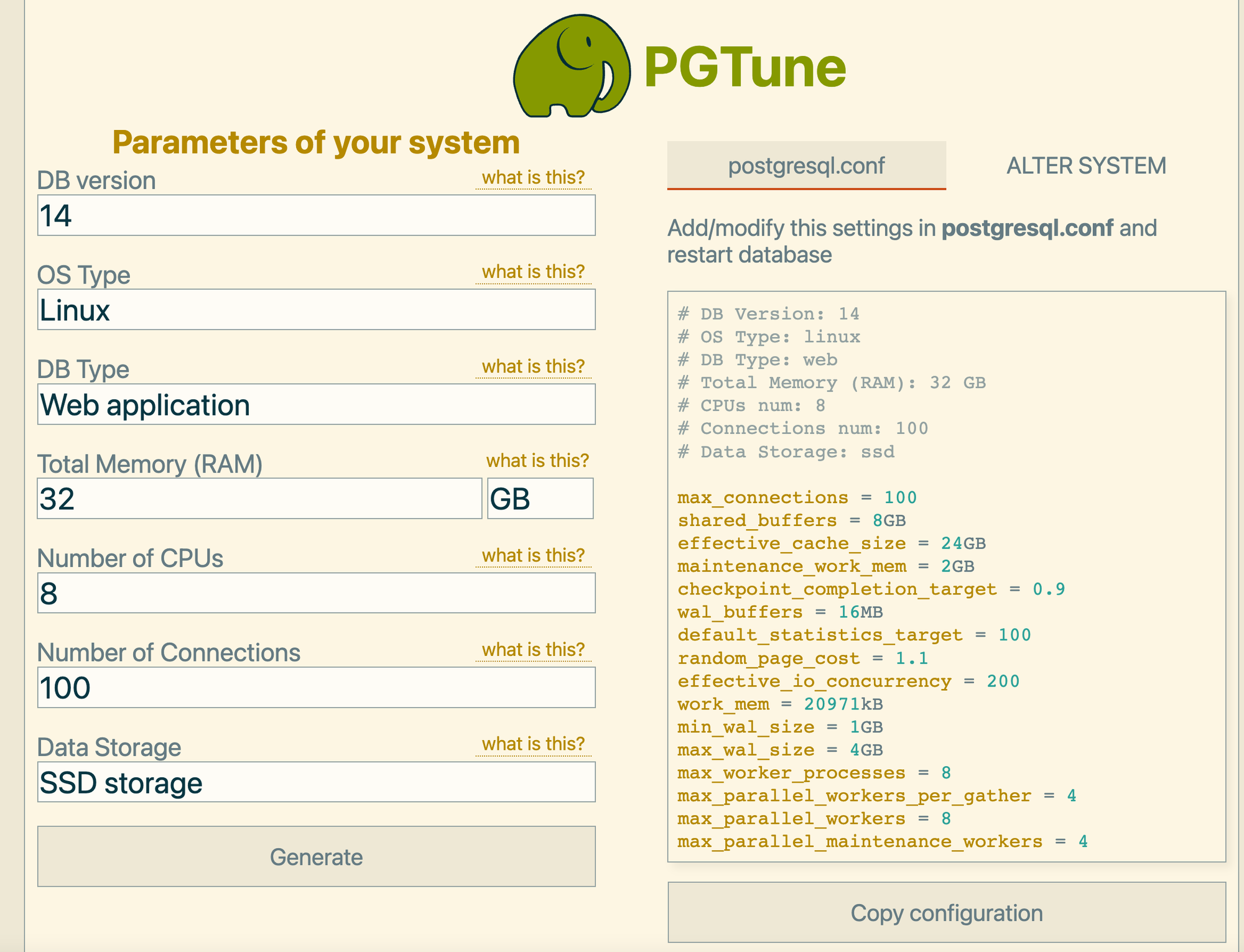
不建议直接去写入conf文件,点击查看ALTER SYSTEM,在SQL中执行一下命令,会在postgresql.auto.conf 中生成配置,然后重启数据库即可
空表创建自增健
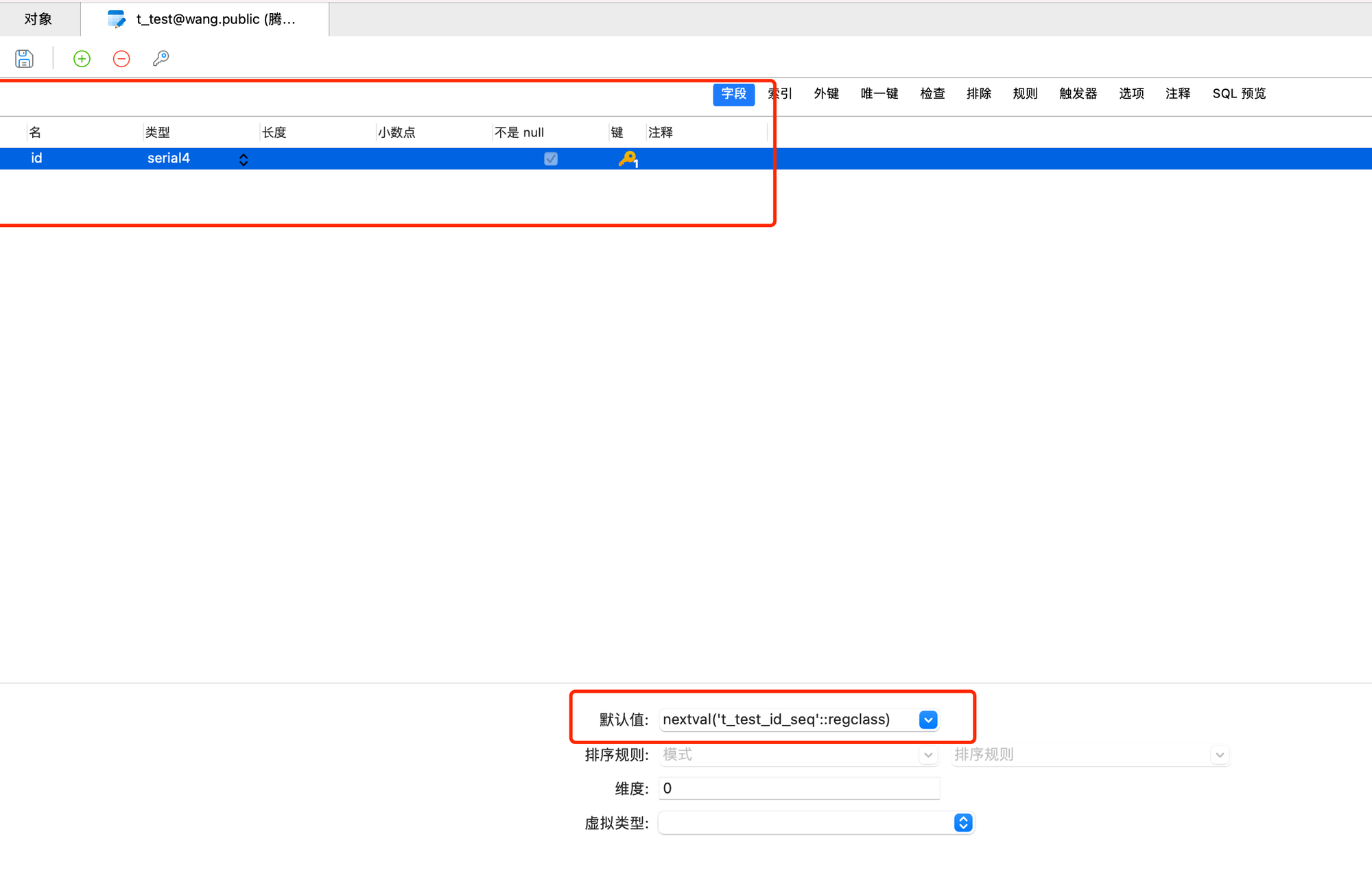
创建一个新的表,添加id字段,类型选为serial4即可(smallserial,serial,bigserial)分别对应2,4,8
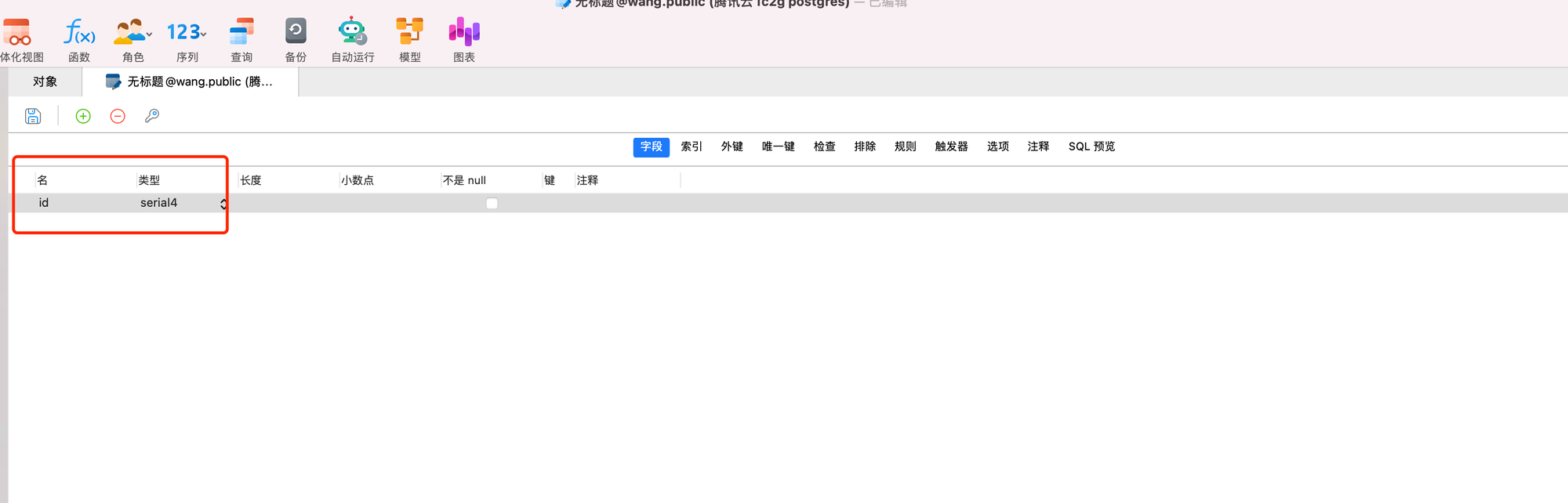
然后点击主键,点击保存,输入表名,就能看到“默认值”的位置有个nextval('t_test_id_seq'::regclass) 这个是pg自动生成的序列,当然也可以自己去创建序列,自定百度
mysql迁移的表结构,更改自增id
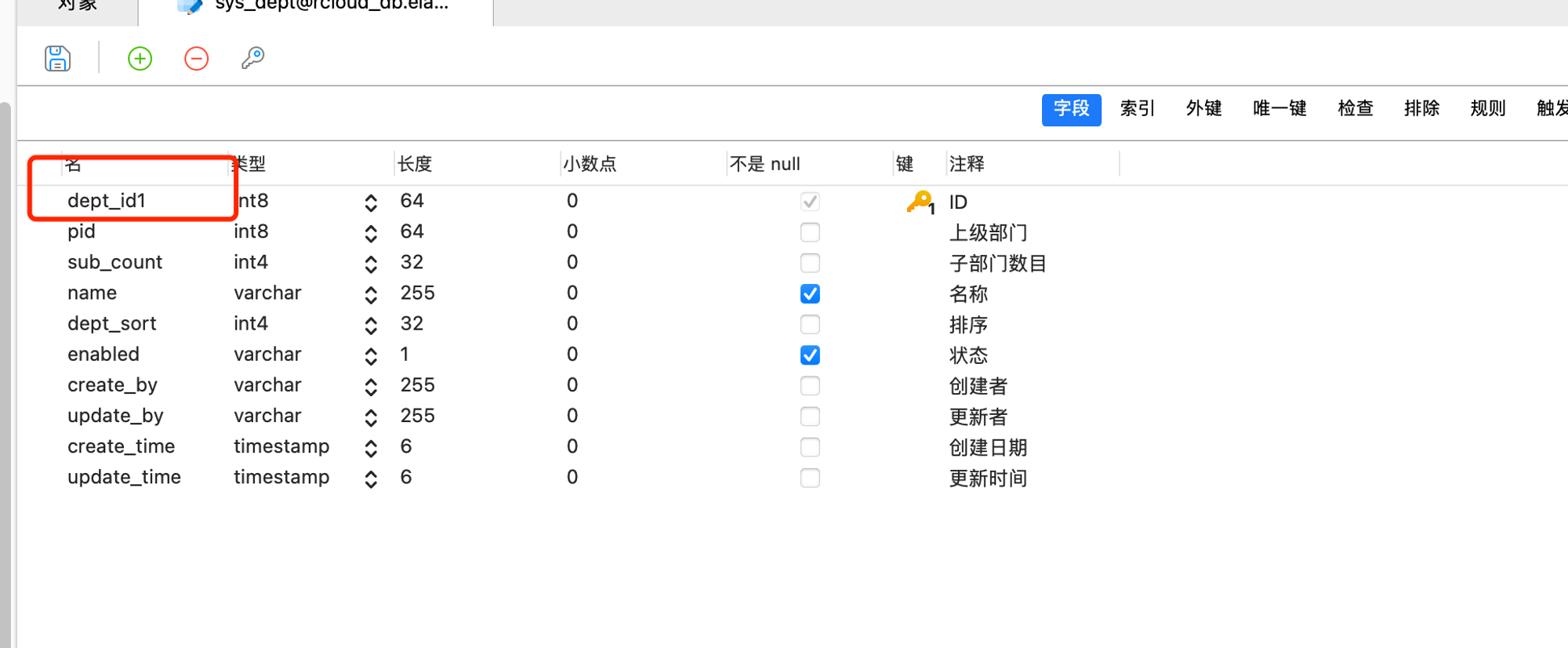
先来看以下mysql迁移完成后的表结构,字段名称和类型基本没啥大问题,默认值是空的,我们就要改这个,
- 首先,我们先给当前的主键更改个新的名字,方便生成序列(sequence), 个体dept_id更改为dept_id1
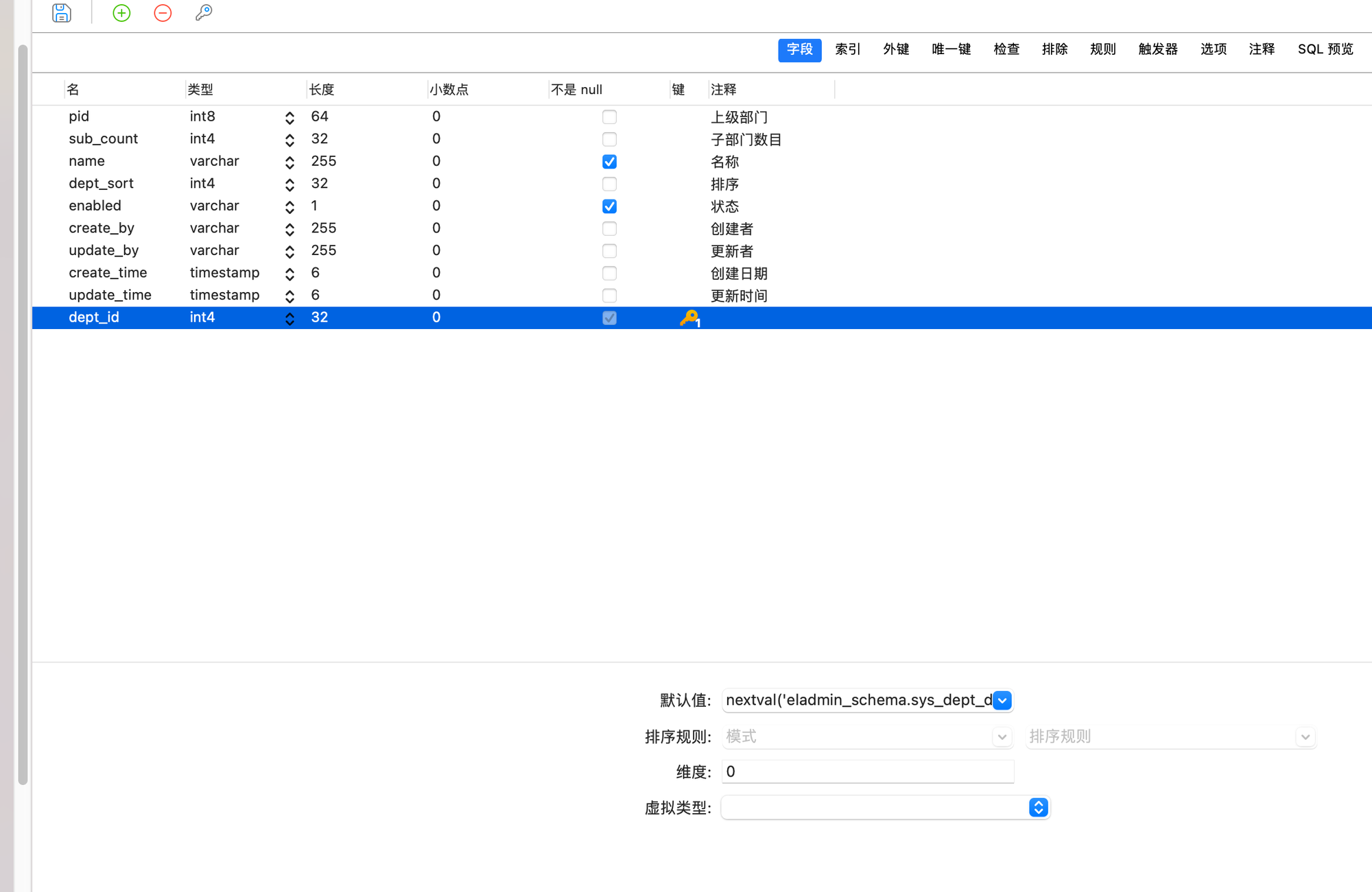
- 新增一个字段叫dept_id 并重复上面空表创建主键的顺序,并且删除dept_id1
迁移数据
Mysql数据库如何迁移到Postgres,基于Navicat15版本操作,如果是版本问题, 请自行解决
相比大家都会有线考虑Navicat的数据迁移,默认情况下,因为mysql和postgres有差异,同步会出一堆问题,所以以下采取的方案是:先同步结构,后同步数据
- 同步结构是用navicat的模型转换
- 同步数据用到数据传输(非数据同步,数据同步只能用同种类数据库)
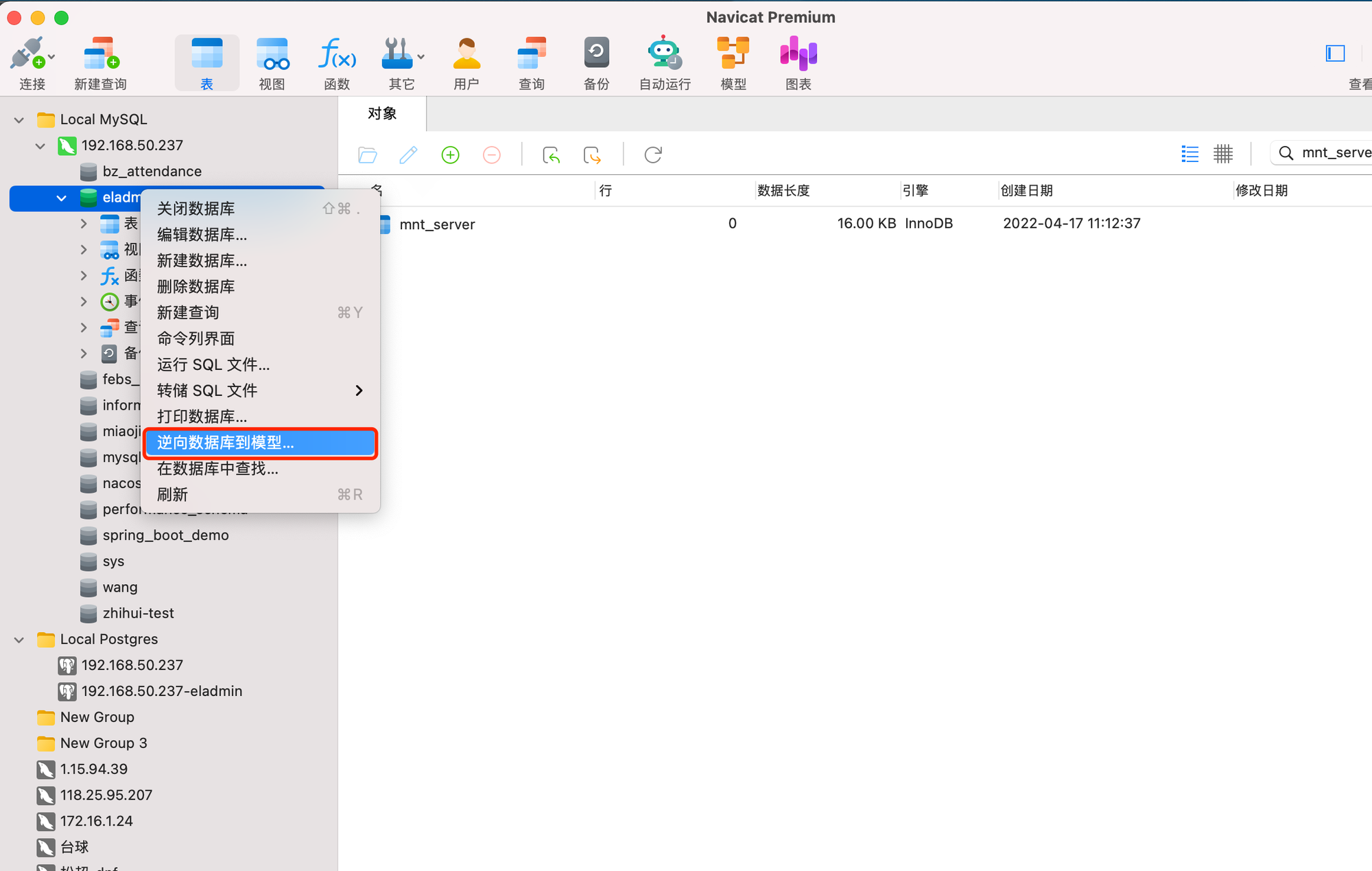
同步表结构
选择数据库,点击右键,选择“逆向数据库到模型”
选择“文件”-“转换模型为”
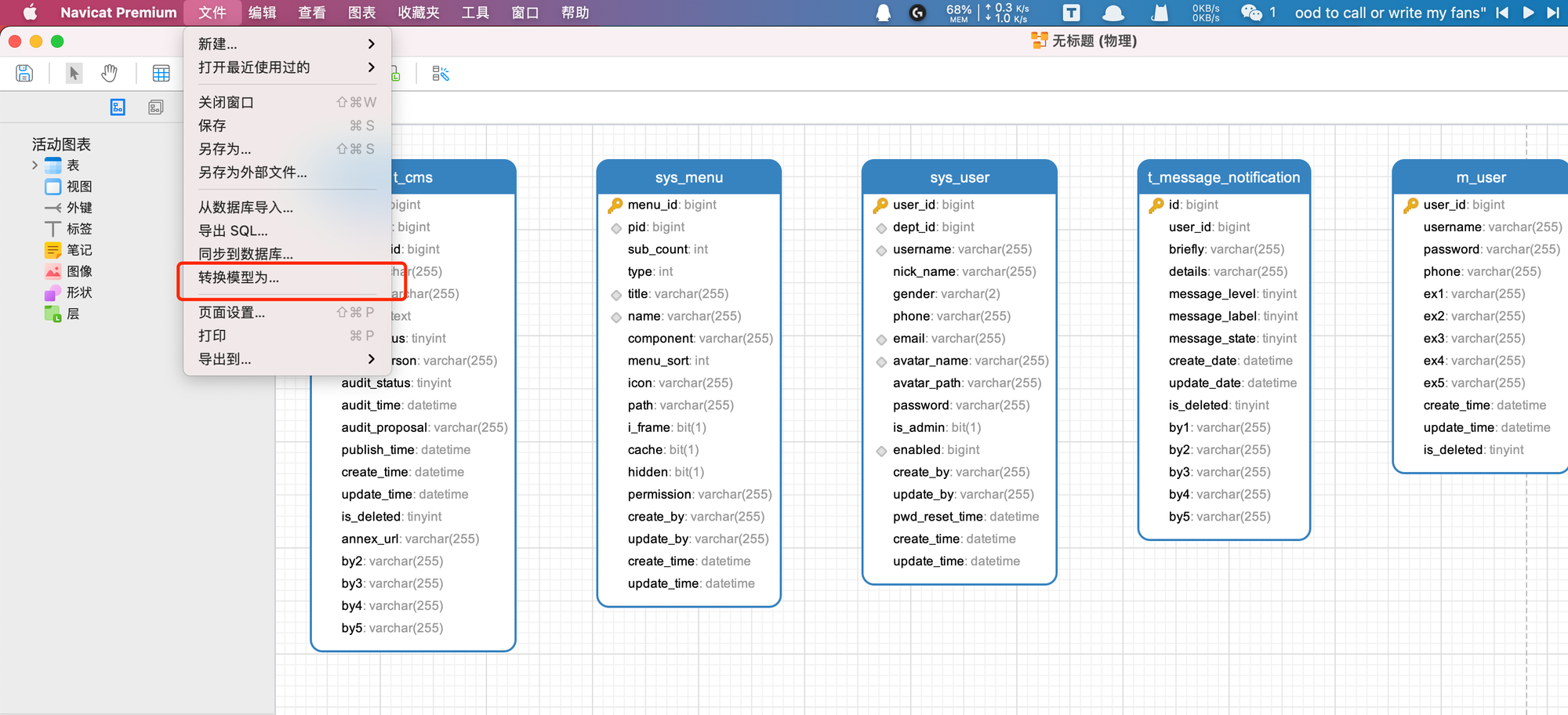
选择数据库为“postgres” 版本号自行选择
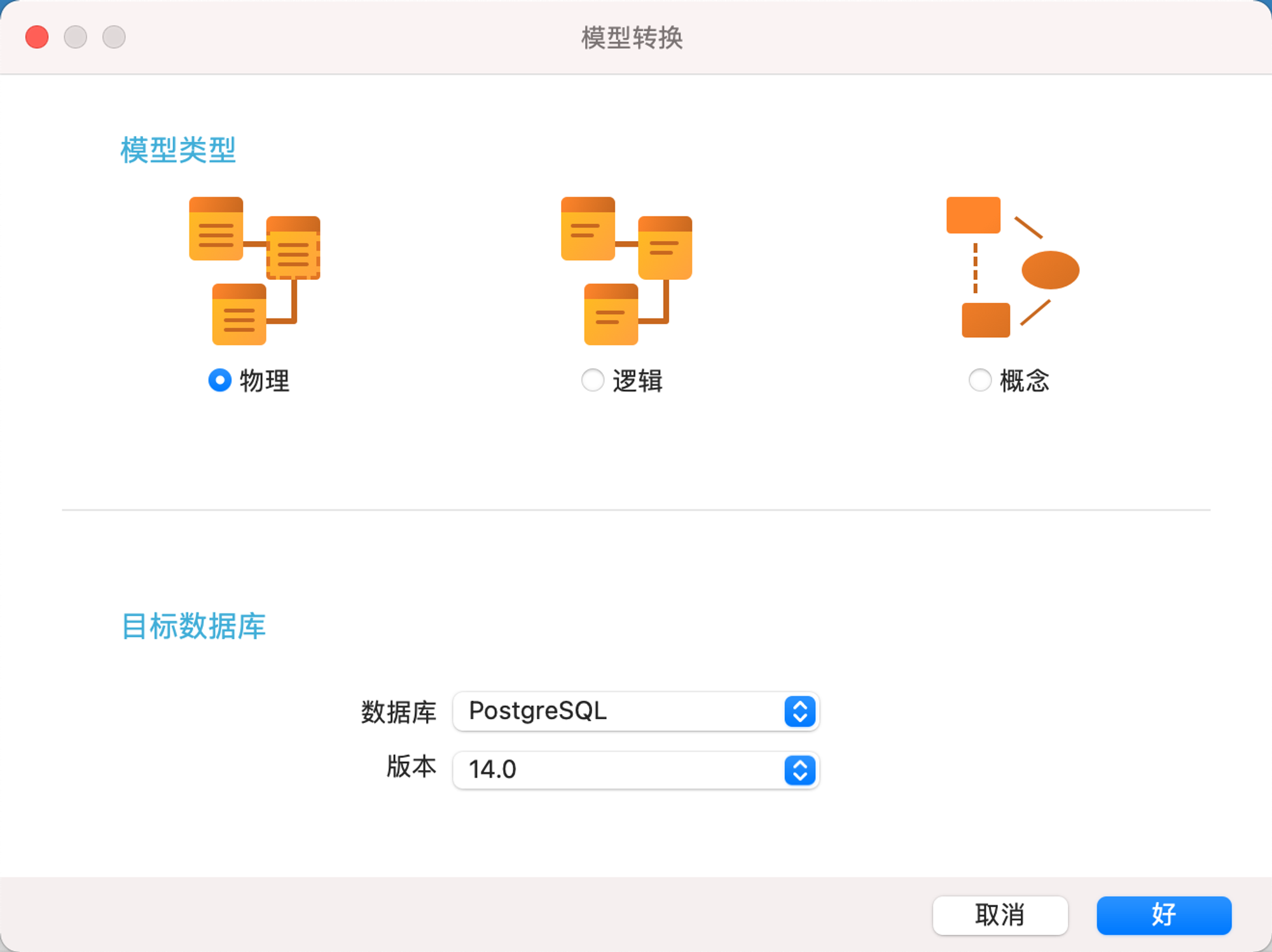
点击确认即可生成表结构,然后选择postgres的表,执行sql即可
同步数据
Navicat中的“工具”-“同步传输”
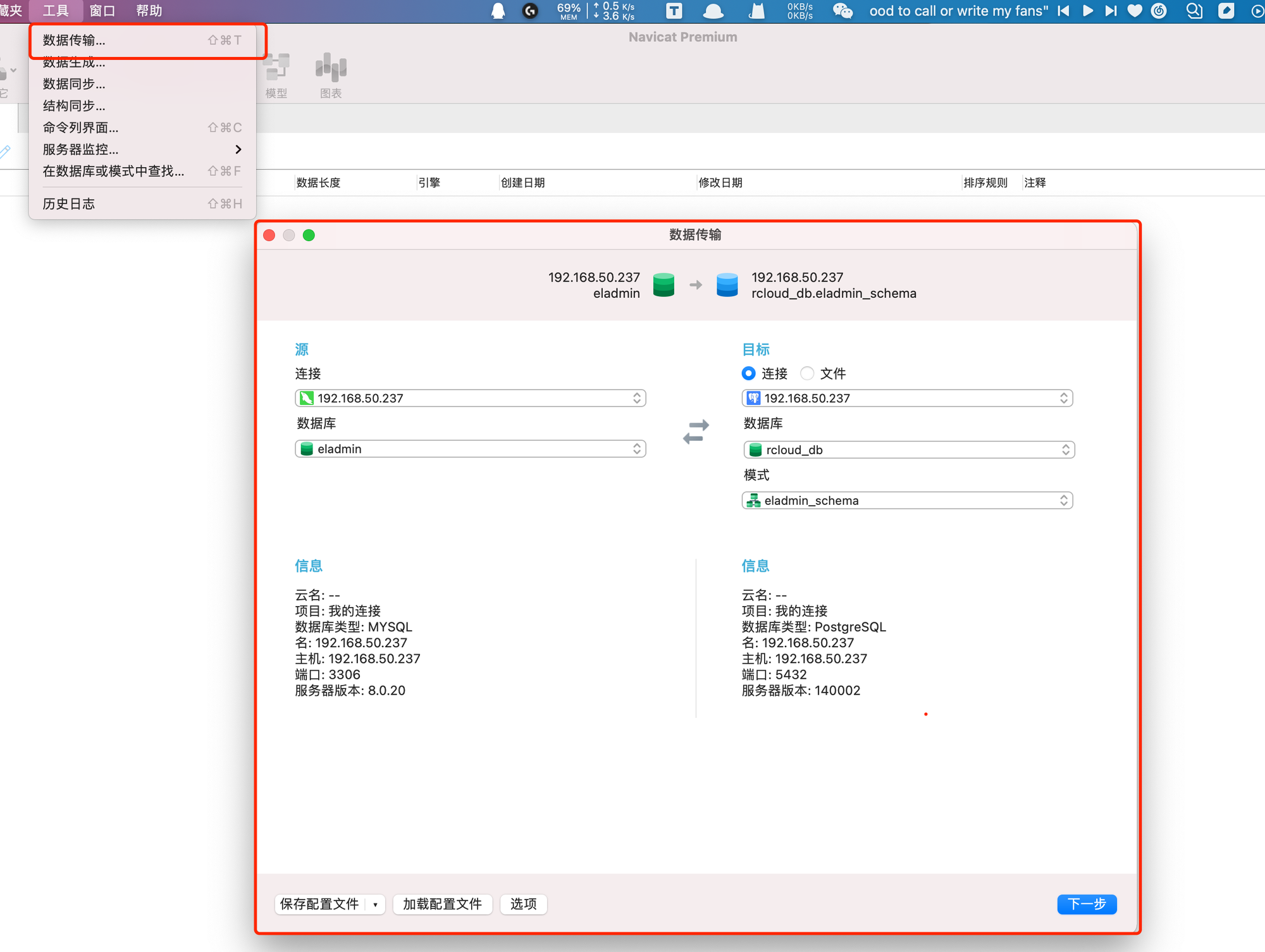
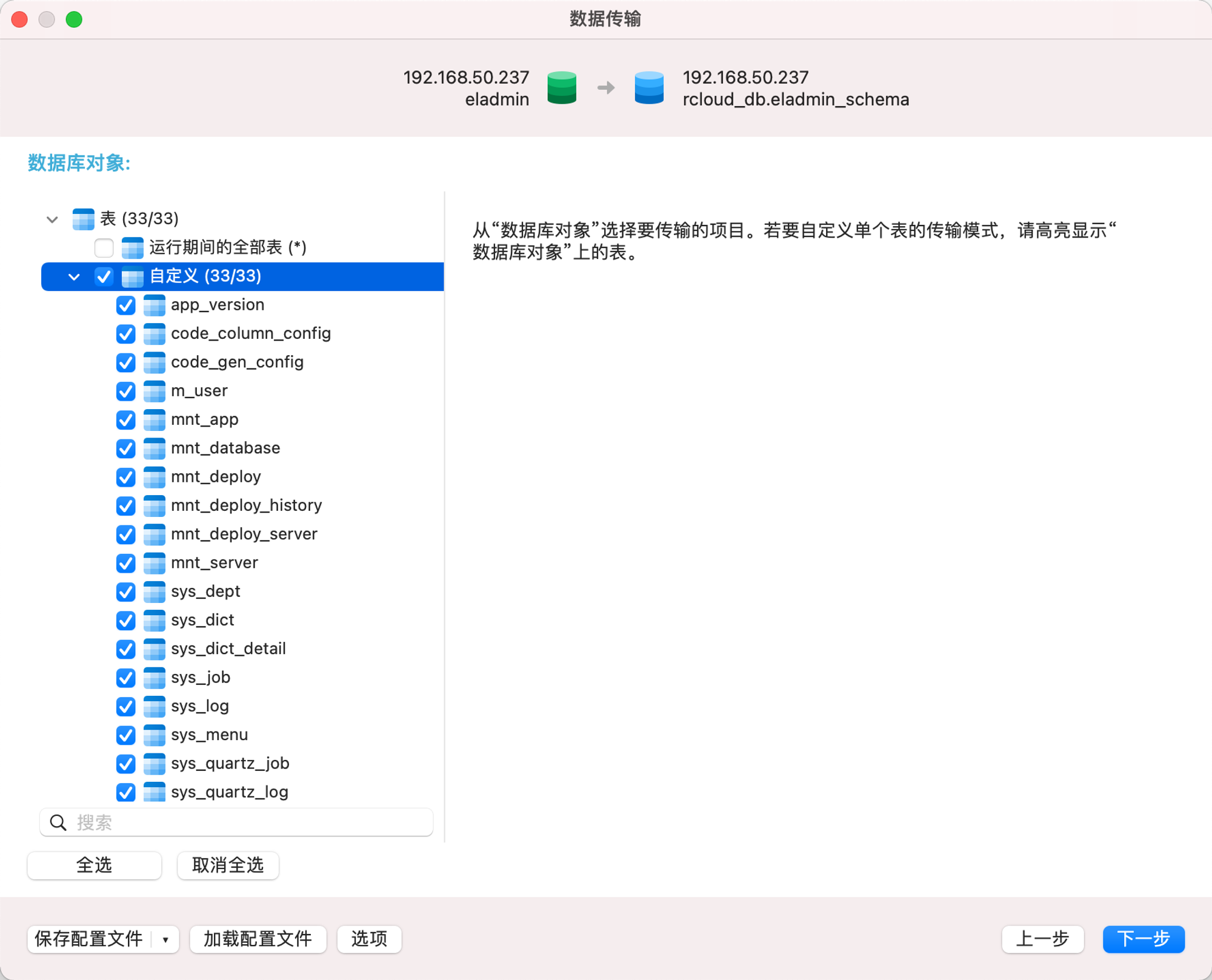
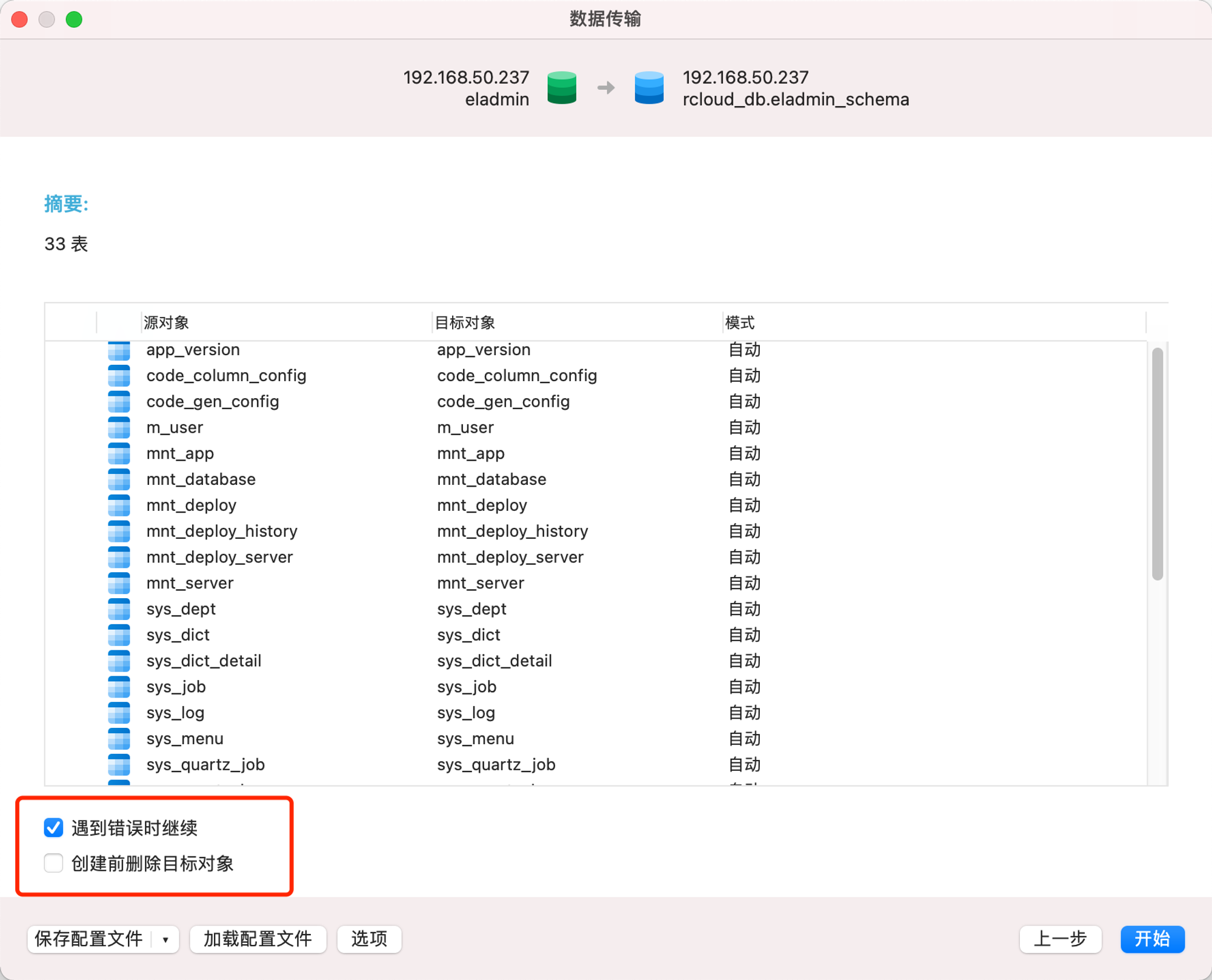
这个位置一定要勾选“遇到错误时继续”,点击开始即可,然后查看日志,可能会报一些错误,但是不影响,去postgres中查看以下表数据
常见差异
类型差异
mysql中常用int的值来标识开/关 比如1表示开启 0表示关闭,在pg中直接用bool类型来解决
简介
在postgres里很多时候想要查看数据库、表、字段的大小,做分析。

查看连接的数据里所有用户表的大小

- Size表示整个表的总大小。
- External Size表示与表关联的主键、索引的大小。
查看每个表、索引、toast表的大小
objecttype:
- r 表示普通表
- i 表示索引
- t 表示toast(The Oversized-Attribute Storage Technique)行外存储表
只查看用户表相关的表、索引、toast表大小
查询某表某列所有项的大小
查询按外键聚合的字段的总大小
json、jsonb类型字段的大小
postgre中text、json、jsonb等类型的字段会在toast表里存储,故通过pg_column_size表查询出来的列数据是经过toast表序列化、压缩之后的大小,这个大小和它们的字符串表示(包括dump文件)会有较大出入,故建议查询大字段的字符串表示时大小,使用octet_length(col):
查询每个表的字段信息
索引规范
数据库表命名规范
此规范包括表名命名规范,索引命名规范,外键命名规范和字段名命名规范。
表名命名规则
数据库表的命名以是名词的复数形式且都为小写,如cities, categories, friends等等
如果表名由几个单词组成,则单词间用下划线(“_”)分割,如subscribed_pois,poi_categories等
表名尽量用全名
表名限制在30个字符内。当表的全名超过30字符时,可用缩写来减少表名的长度,如description –> desc;information –> info;address –> addr等
表字段名命名规则
字段名为小写
字段名为有意义的单词,或单词的缩写
如果字段由几个单词组成,则单词间用下划线(“_”)分割,如client_id,post_code等
字段名限制在30个字符内。当字段名超过30字符时,可用缩写来减少字段名的长度,如description –> desc;information –> info;address –> addr等
索引命名规则
索引须按照IDX_table_<column>_<column>,其中<table>是建立索引的表名,<column>是建立索引的字段名
索引名限制在30个字符内。当索引名超过30字符时,可用缩写来减少索引名的长度,如description –> desc;information –> info;address –> addr等
主键、外键命名规则
主键按照PK_<table>的规则命名,其中<table>为数据库表名
唯一键按照UK_<table>_<column>的规则命名,其中<table>为数据块表名,<column>为字段名
外键按照FK_<pppp>_<cccc>_<nn>的规则命名,其中<pppp>为父表名,<cccc>为子表名,<nn>为序列号
数据库规范化设计的一些基本要求:
一、表中应该避免可为空的列。
虽然表中允许空列,但是,空字段是一种比较特殊的数据类型。数据库在处理的时候,需要进行特殊的处理。如此的话,就会增加数据库处理记录的复杂性。当表中有比较多的空字段时,在同等条件下,数据库处理的性能会降低许多。
解决方法:一是通过设置默认值的形式,来避免空字段的产生。二是若一张表中,允许为空的列比较多,接近表全部列数的三分之一。而且,这些列在大部分情况下,都是可有可无的。若数据库管理员遇到这种情况,建议另外建立一张副表,以保存这些列。
二、表不应该有重复的值或者列。
三、表中记录应该有一个唯一的标识符。
四、数据库对象要有统一的前缀名。
五、尽量只存储单一实体类型的数据。
六、尽量符合数据库的几个范式。
设计规范
所有字段在设计时,除以下数据类型timestamp、image、datetime、smalldatetime、uniqueidentifier、 binary、sql_variant、binary 、varbinary外,必须有默认值。字符型的默认值为一个空字符值串’’;数值型的默认值为数值0;逻辑型的默认值为数值0;
其中:系统中所有逻辑型中数值0表示为“假”;数值1表示为“真”。
datetime、smalldatetime类型的字段没有默认值,必须为NULL。
当字段定义为字符串形时建议使用varchar而不用nvarchar。
字段的描述
数据库中每个字段的描述(Description)如下:
表内的每一个值只能被表达一次
表内的每一行都应当被唯一的标示
表内不应该存储依赖于其他键的非键信息
如果字段事实上是与其它表的关键字相关联而未设计为外键引用,需建索引。
如果字段与其它表的字段相关联,需建索引。
SQL 开发代码规范
我们规定sql语句编码的时候程序员需要遵循以下规范:
a 所有的关键字的所有字母必须大写。如果一个常量由几个词组成,我们规定两个词之间使用下划线(_)来划分。表名、列名、视图名或它们的别名必须和它们的定义保持一致。
b 注释必须要规范。
其他设计技巧
1)避免使用触发器
触发器的功能通常可以用其他方式实现。在调试程序时触发器可能成为干扰。假如你确实需要采用触发器,你最好集中对它文档化。
2)使用常用英语(或者其他任何语言)而不要使用编码在创建下拉菜单、列表、报表时最好按照英语名排序。假如需要编码,可以在编码旁附上用户知道的英语。
3)保存常用信息。让一个表专门存放一般数据库信息非常有用。在这个表里存放数据库当前版本、最近检查/修复、关联设计文档的名称、客户等信息。这样可以实现一种简单机制跟踪数据库,当客户抱怨他们的数据库没有达到希望的要求而与你联系时,这样做对非客户机/服务器环境特别有用。
4)包含版本机制。在数据库中引入版本控制机制来确定使用中的数据库的版本。时间一长,用户的需求总是会改变的。最终可能会要求修改数据库结构。把版本信息直接存放到数据库中更为方便。
5)编制文档。对所有的快捷方式、命名规范、限制和函数都要编制文档。采用给表、列、触发器等加注释的数据库工具。对开发、支持和跟踪修改非常有用。对数据库文档化,或者在数据库自身的内部或者单独建立文档。这样,当过了一年多时间后再回过头来做第2 个版本,犯错的机会将大大减少。
6)测试、测试、反复测试。建立或者修订数据库之后,必须用用户新输入的数据测试数据字段。最重要的是,让用户进行测试并且同用户一道保证选择的数据类型满足商业要求。测试需要在把新数据库投入实际服务之前完成。
7)检查设计。在开发期间检查数据库设计的常用技术是通过其所支持的应用程序原型检查数据库。换句话说,针对每一种最终表达数据的原型应用,保证你检查了数据模型并且查看如何取出数据。
查询包含联合索引的表信息出现重复字段
在一些场景,我们需要查询表的字段信息
例如,有app_version的表
获取表信息sql如下:
查询结果:
column_name | is_nullable | data_type | column_comment | column_key | extra |
id | t | int4 | 主键索引 | PRI | ㅤ |
app_id | t | int4 | app的唯一标识 | ㅤ | ㅤ |
app_name | t | varchar | app的名称 | ㅤ | ㅤ |
version | t | varchar | 版本号 as 1.0.0 | ㅤ | ㅤ |
build | t | int8 | 构建版本 as 400 | ㅤ | ㅤ |
title | t | varchar | 版本标题 as 3.0版本隆重登场 | ㅤ | ㅤ |
info | t | varchar | 版本更新内容,主要在app上展示 | ㅤ | ㅤ |
min_version | f | varchar | 最低支持的版本 as 1.0.2 | ㅤ | ㅤ |
update_type | t | varchar | 更新方式 forcibly = 强制更新, solicit = 弹窗确认更新, silent = 静默更新 | ㅤ | ㅤ |
platform | t | varchar | 平台 ios/android/app(ios&android) | ㅤ | ㅤ |
wgt_url | f | varchar | wgt | ㅤ | ㅤ |
apk_url | f | varchar | apk | ㅤ | ㅤ |
published | t | int2 | 是否发布 0=未发布 1=发布 | ㅤ | ㅤ |
archived | t | int2 | 是否归档 0=未归档 1=归档 可在拦截器判断,归档的版本禁止提供服务 | ㅤ | ㅤ |
is_deleted | t | int2 | 逻辑删除 0=未删除 1=删除 | ㅤ | ㅤ |
is_latest_release | t | varchar | 最新版本 0=不是最新 1=最新 | ㅤ | ㅤ |
update_time | f | timestamp | 更新时间 | ㅤ | ㅤ |
create_time | t | timestamp | 创建时间 | ㅤ | ㅤ |
先说一下表字段信息,官方文档 http://www.postgres.cn/docs/14/catalogs.html
- pg_attribute http://www.postgres.cn/docs/14/catalog-pg-attribute.html 目录
pg_attribute存储有关表列的信息。数据库中的每一个表的每一个列都恰好在pg_attribute中有一行。(这其中也会有索引的属性项,并且事实上所有具有pg_class项的对象在这里都有属性项) entries.)
- pg_class http://www.postgres.cn/docs/14/catalog-pg-class.html 目录
pg_class记录表和几乎所有具有列或者像表的东西。这包括索引(但还要参见pg_index)、序列(但还要参见pg_sequence)、视图、物化视图、组合类型和TOAST表,参见relkind。下面,当我们提及所有这些类型的对象时我们使用“关系”。并非所有列对于所有关系类型都有意义。
- pg_index http://www.postgres.cn/docs/14/catalog-pg-index.html 目录
pg_index包含关于索引的部分信息。其他信息大部分在pg_class中。
- pg_type http://www.postgres.cn/docs/14/catalog-pg-type.html 目录
pg_type存储有关数据类型的信息。基类和枚举类型(标度类型)使用CREATE TYPE创建,而域使用CREATE DOMAIN创建。数据库中的每一个表都会有一个自动创建的组合类型,用于表示表的行结构。也可以使用CREATE TYPE AS创建组合类型。
当出现联合索引的情况具体的查询,会造成重复结果,如下
column_name | is_nullable | data_type | column_comment | column_key | extra |
id | t | int4 | 主键索引 | PRI | ㅤ |
id | t | int4 | 主键索引 | ㅤ | ㅤ |
app_id | t | int4 | app的唯一标识 | ㅤ | ㅤ |
app_id | t | int4 | app的唯一标识 | ㅤ | ㅤ |
app_name | t | varchar | app的名称 | ㅤ | ㅤ |
app_name | t | varchar | app的名称 | ㅤ | ㅤ |
version | t | varchar | 版本号 as 1.0.0 | ㅤ | ㅤ |
version | t | varchar | 版本号 as 1.0.0 | ㅤ | ㅤ |
build | t | int8 | 构建版本 as 400 | ㅤ | ㅤ |
build | t | int8 | 构建版本 as 400 | ㅤ | ㅤ |
title | t | varchar | 版本标题 as 3.0版本隆重登场 | ㅤ | ㅤ |
title | t | varchar | 版本标题 as 3.0版本隆重登场 | ㅤ | ㅤ |
info | t | varchar | 版本更新内容,主要在app上展示 | ㅤ | ㅤ |
info | t | varchar | 版本更新内容,主要在app上展示 | ㅤ | ㅤ |
min_version | f | varchar | 最低支持的版本 as 1.0.2 | ㅤ | ㅤ |
min_version | f | varchar | 最低支持的版本 as 1.0.2 | ㅤ | ㅤ |
update_type | t | varchar | 更新方式 forcibly = 强制更新, solicit = 弹窗确认更新, silent = 静默更新 | ㅤ | ㅤ |
update_type | t | varchar | 更新方式 forcibly = 强制更新, solicit = 弹窗确认更新, silent = 静默更新 | ㅤ | ㅤ |
platform | t | varchar | 平台 ios/android/app(ios&android) | ㅤ | ㅤ |
platform | t | varchar | 平台 ios/android/app(ios&android) | ㅤ | ㅤ |
wgt_url | f | varchar | wgt | ㅤ | ㅤ |
wgt_url | f | varchar | wgt | ㅤ | ㅤ |
apk_url | f | varchar | apk | ㅤ | ㅤ |
apk_url | f | varchar | apk | ㅤ | ㅤ |
published | t | int2 | 是否发布 0=未发布 1=发布 | ㅤ | ㅤ |
published | t | int2 | 是否发布 0=未发布 1=发布 | ㅤ | ㅤ |
archived | t | int2 | 是否归档 0=未归档 1=归档 可在拦截器判断,归档的版本禁止提供服务 | ㅤ | ㅤ |
archived | t | int2 | 是否归档 0=未归档 1=归档 可在拦截器判断,归档的版本禁止提供服务 | ㅤ | ㅤ |
is_deleted | t | int2 | 逻辑删除 0=未删除 1=删除 | ㅤ | ㅤ |
is_deleted | t | int2 | 逻辑删除 0=未删除 1=删除 | ㅤ | ㅤ |
is_latest_release | t | varchar | 最新版本 0=不是最新 1=最新 | ㅤ | ㅤ |
is_latest_release | t | varchar | 最新版本 0=不是最新 1=最新 | ㅤ | ㅤ |
update_time | f | timestamp | 更新时间 | ㅤ | ㅤ |
update_time | f | timestamp | 更新时间 | ㅤ | ㅤ |
create_time | t | timestamp | 创建时间 | ㅤ | ㅤ |
create_time | t | timestamp | 创建时间 | ㅤ | ㅤ |
这是我们可以通过,因为pg_index中有两条索引记录,如下
查询表索引信息
查询结果,可以看到indkey这一列 由具体的key位置, 多个点话,就是联合索引,就是此处导致,我们只需要把sql稍作优化。
在pg_index官方文档中说明,
indisunique 如为真, 这是唯一索引
复制方案
根据不同的场景选择不同的方案
Postgres 中使用 Zhparser 插件进行中文全文检索
更改owner
1.更改所有表的Owner
2.更改序列Owner
参考资料
- pg中文社区 https://github.com/postgres-cn/pgdoc-cn wiki中有具体翻译进度